Tornado 源码分析
发布于 2016-01-27 01:58:32 | 353 次阅读 | 评论: 0 | 来源: 分享
Tornado Python Web应用开发框架
Tornado的全称是Torado Web Server,从名字上看就可知道它可以用作Web服务器,但同时它也是一个Python Web的开发框架。最初是在FriendFeed公司的网站上使用,FaceBook收购了之后便开源了出来。
Tornado 所谓的异步:就是你调用我之后,我发现数据没准备好,那我就不处理,而是跳到程序的其他地方继续执行,等数据准备好之后再切回来继续执行。Tornado 的 IOLoop 就是一个总调度器,汇总了所有的 events 和 callbacks,然后同步执行。这会整体生提升性能,但不会降低单个请求的响应时间。
本文主要包括:
tornado.httpclient.AsyncHTTPClient的实现tornado.gen.engine的实现tornado.gen.YieldFuture和tornado.concurrent.Future的作用
Tornado 在 2.0 时候,已经完整实现非阻塞 HTTP 客户端,发起 HTTP 请求可以实现异步效果。
从一个简单的异步实例开始:
# 代码一
class AsyncHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
def get(self):
http_client = AsyncHTTPClient()
http_client.fetch("http://example.com",
callback=self.on_fetch)
def on_fetch(self, response):
self.write("Downloaded!")
self.finish()
tornado.web.asynchronous
其中 tornado.web.asynchronous 装饰器很简单,就是设置 self._auto_finish = False,这样当 AsyncHandler.get() 执行完之后,connection socket 不会被 close,需要主动调用 self.finish()。在保持连接不关闭的情况下,把控制权让出去,等数据就绪之后再切回来,使异步实现成为可能。 下面是 asynchronous 简化后的代码:
# 代码二:
def asynchronous(method):
@functools.wraps(method)
def wrapper(self, *args, **kwargs):
if self.application._wsgi:
raise Exception("@asynchronous is not supported for WSGI apps")
self._auto_finish = False
return method(self, *args, **kwargs)
return wrapper
SimpleAsyncHTTPClient
AsyncHTTPClient 的处理流程,简单概括就是:与 HTTP Server 建立连接,等拿到 response 后再来调用回调函数 on_fetch。首先通过创建非阻塞的 socket 连接,然后放入到 ioloop 中,当数据可写/可读之后再接着处理。
「代码一」中调用 AsyncHTTPClient() 时,其实生成的是 SimpleAsyncHTTPClient 对象,有兴趣可以了解下实现。
下面是「代码一」执行流程图:
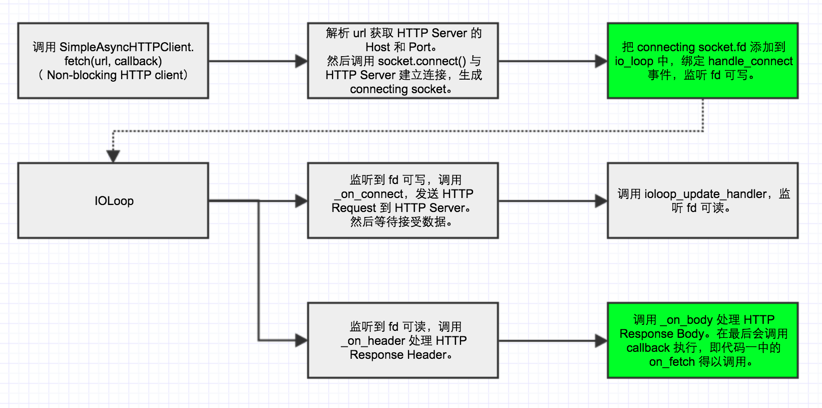
SimpleAsyncHTTPClient 的实现和 HTTPServer 很相似。
Tornado 3.0 中的 AsyncHTTPClient 的主要不同是:在 _on_body 处理完 Response Body 之后会调用 handle_response 把 reponse 设置给 future,并将 future 对象返回。AsyncHTTPClient.fetch 简化后的代码:
def fetch(request)
def handle_response(response):
if response.error:
future.set_exception(response.error)
else:
future.set_result(response)
self.fetch_impl(request, handle_response)
return future
gen.engine 的实现:
以下的代码分析都是基于 Tornado 3.0。
使用 gen.engine 优化后的代码:
class GenEngineAsyncHandler(tornado.web.RequestHandler):
@tornado.web.asynchronous
@tornado.gen.engine
def get(self):
http_client = AsyncHTTPClient()
response = yield http_client.fetch("http://example.com")
self.write("Downloaded!")
self.finish()
其中 gen.engine 的作用就是把异步中 callback 的写法通过 yield 替代。
以上代码的详细处理流程:
- 在
gen.engine中,调用result = func(*args, **kwargs),生成一个 generator。因为get中包含yield,所以当函数被调用时,会生成 generator 对象。但是函数并不会执行,需要通过调用next或send来执行。具体参考 generator 的用法。engine简化后的代码就是:def engine(func): @functools.wraps(func) def wrapper(*args, **kwargs): result = func(*args, **kwargs) runner = Runner(result, final_callback) runner.run() - 其中
Runner.run的作用:开始或重新启动 generator,直到YieldPoint没有数据为止。runner 通过self.yield_point来记录 generator 的执行状态,这样再次调用 run() 的时候,就可以接着上次的地方往下执行。def run(): while True: if not self.yield_point.is_ready(): return next = self.yield_point.get_result() yielded = self.gen.send(next) except (StopIteration, Return) as e: self.final_callback() self.yield_point.start(self)- 第一次调用
yielded = self.gen.send(next)时 next 为 None,执行http_client.fetch(),生成一个 future 对象。 - 第二次调用
yielded = self.gen.send(next)时,会先调用next = self.yield_point.get_result(),从future.result取出数据,然后 send 给 generator。 get接受到 runner send 过来的数据后,接着往后执行,执行完整个get函数后。generator 会抛出StopIteration异常,调用runner.final_callback()处理。
- 第一次调用
YieldFuture用于记录和处理 generator 执行 yield 之后的状态,方便 runner 获取数据,并接着执行。- 当
future还没被set_result时,yield_point.is_ready()会返回False,runner.run()在下次循环中直接结束。 - 当
future已经被set_result,可以通过yield_point.get_result()获取 result(即:response)。 yield_point.start的作用就是把runner.result_callback()添加到future.callbacks中。future.callbacks只是做临时保存,当 future 被set_result之后,runner.result_callback()才会添加到 ioloop 中得以执行。
- 当
Future用于保存异步调用中的 callbacks 和 result。当被调用set_result之后,会遍历 callbacks 挨个执行。当 callback 被添加到 future 中,表示 callback 已处于 pending 状态。set_result发生后,callback 会切换到 running 状态,得到执行。class Future(object): def set_result(self, result): self._result = result self._set_done() def _set_done(self): self._done = True for cb in self._callbacks: # TODO: error handling cb(self) self._callbacks = None
QA:
Future.callbacks与IOLoop.callbacks的区别?
IOLoop.add_future为什么不直接调用IOLoop.add_callback,而是需要先调用Future.add_done_callback?
future 会临时保存 callbacks,等 future._result 被设置后,才会把 callbacks 添加到 io_loop.callbacks 中执行。
因为 callback 只要放入ioloop.callbacks就意味在 ioloop 的下一次循环会被执行。future.result不一定有值,而runner.result_callback()需要在future.result有值后才继续执行,所以runner.result_callback会暂时保存在future.callbacks,等待future.result有值后再继续执行。