PostgreSQL之分区表(partitioning)
发布于 2017-07-19 22:06:05 | 162 次阅读 | 评论: 0 | 来源: 网友投递
这里有新鲜出炉的PostgreSQL指南,程序狗速度看过来!
PostgreSQL关系型数据库管理系统
PostgreSQL是以加州大学伯克利分校计算机系开发的 POSTGRES,现在已经更名为PostgreSQL,版本 4.2为基础的对象关系型数据库管理系统(ORDBMS)。
通过合理的设计,可以将选择一定的规则,将大表切分多个不重不漏的子表,这就是传说中的partitioning。比如,我们可以按时间切分,每天一张子表,比如我们可以按照某其他字段分割,总之了就是化整为零,提高查询的效能
PostgreSQL有一项非常有用的功能,分区表,或者partitioning。当某个TABLE的记录非常的多,千万甚至更多的时候,我们其实需要将他分割成子表。一个庞大的TABLE,就像水果仓库杂乱无章地堆放着无数的苹果桃子和桔子,查找不方便,性能降低,比较合理的做法是将仓库分成三个子区域,分表放苹果桃子和桔子。一张大表就变成了三个小表的集合。
通过合理的设计,可以将选择一定的规则,将大表切分多个不重不漏的子表,这就是传说中的partitioning。比如,我们可以按时间切分,每天一张子表,比如我们可以按照某其他字段分割,总之了就是化整为零,提高查询的效能。
怎么实现这个分区表的功能呢?
1 建立大表。
2 创建分区继承
3 定义Rule或者Trigger?
下面根据一个简单的例子,描述这个过程。我们将学生按照低于60分和不低于60分切分成两张子表。
1 建立大表
CREATE TABLE student (student_id bigserial, name varchar(32), score smallint)2 创建分区继承。
CREATE TABLE student_qualified (CHECK (score >= 60 )) INHERITS (student) ;
CREATE TABLE student_nqualified (CHECK (score < 60)) INHERITS (student) ;创建了两个分区表,student_qualified和student_nqualified,继承了大表student的一切字段,同时设定了约束,即CHECK条件。
3 定义Rule或者Trigger。
虽然我们定义了CHECK条件,但是往student插入数据时,PostgreSQL并不能根据score是否低于60插入的正确的子表,原因是,你并没有定义这种规则,来告诉数据这么做。我们需要定义Rule或者Trigger,将数据插入到正确的分区表。
先看下Rule的定义:
CREATE OR REPLACE RULE insert_student_qualified
AS ON INSERT TO student
WHERE score >= 60
DO INSTEAD
INSERT INTO student_qualified VALUES(NEW.*);
CREATE OR REPLACE RULE insert_student_nqualified
AS ON INSERT TO student
WHERE score < 60
DO INSTEAD
INSERT INTO student_nqualified VALUES(NEW.*);这两个Rule告诉了PostgreSQL,当往总表插数据的时候,如果是score< 60,则插入student_nqualified,如果score>=60,则插入student_qualified.注意了,这个分割一定要不重不漏,如果我们不小心将>=60条件的“=”丢掉,等于60分的记录将会录入大表student,不在任何一个分区表中。
我们插入一些记录:
INSERT INTO student (name,score) VALUES('Jim',77);
INSERT INTO student (name,score) VALUES('Frank',56);
INSERT INTO student (name,score) VALUES('Bean',88);
INSERT INTO student (name,score) VALUES('John',47);
INSERT INTO student (name,score) VALUES('Albert','87');
INSERT INTO student (name,score) VALUES('Joey','60');我们看下数据分布情况,是否分布到了正确的的分区表:
SELECT p.relname,c.tableoid,c.*
FROM student c, pg_class p
WHERE c.tableoid = p.oid输出如下:
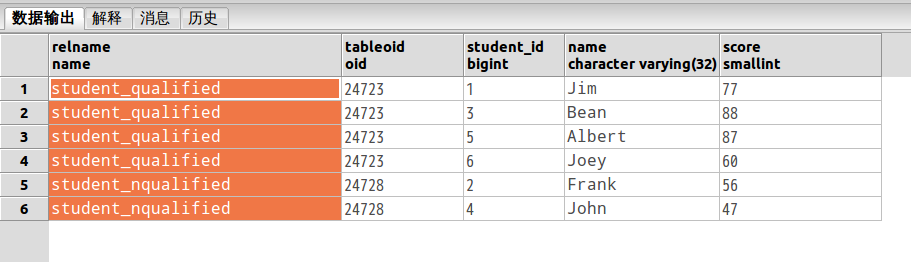
我们看到,虽然我们插入的是大表,但是数据却存在了对应的分区子表。符合我们的期望。同时还不影响查询。
Rule是一个分流的办法,还有TRIGGER也能做到让正确的数据流向正确的分区子表。
首先我们定义个function。
CREATE OR REPLACE FUNCTION student_insert_trigger()
RETURNS TRIGGER AS
$$
BEGIN
IF(NEW.score >= 60) THEN
INSERT INTO student_qualified VALUES (NEW.*);
ELSE
INSERT INTO student_nqualified VALUES (NEW.*);
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql ;然后定义TRIGGER,当插入到student之前,就会触发trigger:
CREATE TRIGGER insert_student
BEFORE INSERT ON student
FOR EACH row
EXECUTE PROCEDURE student_insert_trigger() ;我们首先通过删除TABLE student,测试下trigger方式。
DROP TABLE STUDENT CASCADE
CREATE TABLE student (student_id bigserial, name varchar(32), score smallint) ;
CREATE TABLE student_qualified (CHECK (score >= 60 )) INHERITS (student) ;
CREATE TABLE student_nqualified (CHECK (score < 60)) INHERITS (student) ;然后执行定义FUNCTION和定义TRIGGER的语句。就可以查看了。
为了确认我们的触发器的确触发了,我们打开存储过程的统计开关:
在postgresql.conf中,找到track_functions,改成all
track_functions = all
插入之前先看下function student_insert_trigger的统计信息:

执行插入:
INSERT INTO student (name,score) VALUES('Jim',77);
INSERT INTO student (name,score) VALUES('Frank',56);
INSERT INTO student (name,score) VALUES('Bean',88);
INSERT INTO student (name,score) VALUES('John',47);
INSERT INTO student (name,score) VALUES('Albert','87');
INSERT INTO student (name,score) VALUES('Joey','60');插入后,看下function student_insert_trigger的统计信息

我们看到trigger触发了6次。
执行下查询:
SELECT p.relname,c.tableoid,c.*
FROM student c, pg_class p
WHERE c.tableoid = p.oid输出如下:
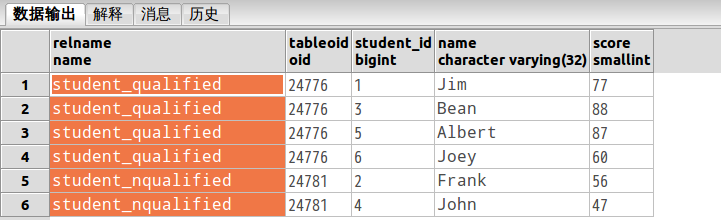
参考文献